With the ongoing Big data revolution, and the impending Internet of Things revolution, there has been a renewed enthusiasm in “innovation” around data. Similar to the Labs concept started by Google (think Gmail Beta based on Ajax, circa 2004), more and more organizations, business communities, governments and countries are setting up Labs to foster innovation in data and analytics technologies. The idea behind these “data innovation labs” is to develop avant-garde data and analytics technologies and products in an agile fashion and move quickly from concept to production. Given the traditional bureaucratic setup in large organizations and governments, these Labs stand a better chance of fostering a culture of innovation, due to their being autonomous entities and their startup-mode culture leveraging agile methodologies.
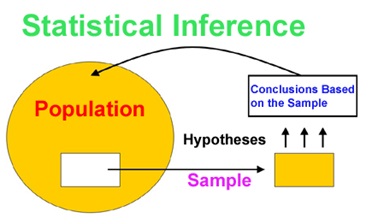
Statistical inference is concerned primarily with understanding the quality of parameter estimates.
The sampling distribution represents the distribution of the point estimates based on samples of a fixed size from a certain population. It is useful to think of a particular point estimate as being drawn from such a distribution. Understanding the concept of a sampling distribution is central to understanding statistical inference.
A sample statistic is a point estimate for a population parameter, e.g. the sample mean is used to estimate the population mean. Note that point estimate and sample statistic are synonymous. Recognize that point estimates (such as the sample mean) will vary from one sample to another, and define this variability as sampling variability (sometimes also called sampling variation).
With each of the big 3 Hadoop vendors - Cloudera, Hortonworks and MapR each providing their own Hadoop sandboxvirtual machines (VMs), trying out Hadoop today has become extremely easy. For a developer, it is extremely useful to download a get started with one of these VMs and try out Hadoop to practice data science right away.
However, with the core Apache Hadoop, these vendors package their own software into their distributions, mostly for the orchestration and management, which can be a pain due to the multiple scattered open-source projects within the Hadoop ecosystem. e.g. Hortonworks includes the open-source Ambari while Cloudera includes its own Cloudera Manager for orchestrating Hadoop installations and managing multi-node clusters.
How does the typical data science project life-cycle look like?
This post looks at practical aspects of implementing data science projects. It also assumes a certain level of maturity in big data (more on big data maturity models in the next post) and data science management within the organization. Therefore the life cycle presented here differs, sometimes significantly from purist definitions of ‘science’ which emphasize the hypothesis-testing approach. In practice, the typical data science project life-cycle resembles more of an engineering view imposed due to constraints of resources (budget, data and skills availability) and time-to-market considerations.
Sometime back I presented a webinar on BrightTalk. The slides for the talk have now been uploaded on Slideshare. The talk focused more on changes in digital technology disrupting businesses, the effect of Big Data, the FOMO (Fear of missing out) effect on big business - and what it meant for changes to the way we do business intelligence in the digital era.