I recently gave a talk on data processing with Apache Spark using R and Python. tl;dr - the slides and presentation can be accessed below (free registration):
As noted in my previous post, Spark has become the defacto standard for big data applications and has been adopted quickly by the industry. See Cloudera’s One Platform initiative blog post by CEO Mike Olson for their commitment to Spark.
Over the past few weeks, we’ve had several conversations in our data lab regarding data engineering problems and day to day problems we face with unsupervised data scientists who find it difficult to deploy their code into production.
The opinions from business seemed to cluster around a tacit definition of data scientists as researchers, primarily from statistics or mathematics backgrounds, who are experienced in machine learning algorithms and often in some domain areas specific to our business, (e.g. actuaries in insurance), but not necessarily having skills of writing production-ready code.
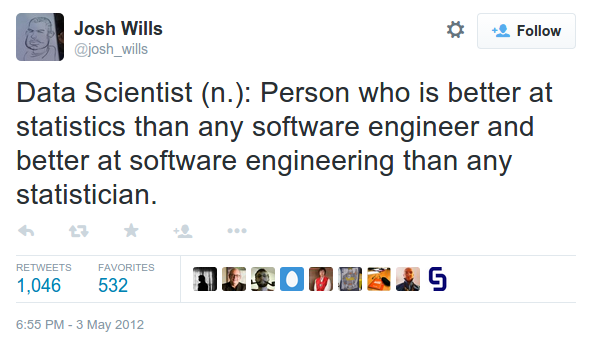
The key driver behind the somewhat opposing strain of thought came from the developers and data engineers who often quoted Cloudera’s Director of Data Science - Josh Wills - famous for his “definition of a data scientist tweet”:
“Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.”
I presented a talk last week introducing Data Science and associated topics to some enthusiasts.
Here’s a slide deck I created quickly with markdown using Swipe - a start-up building HTML5 presentation tools.
The contents include:
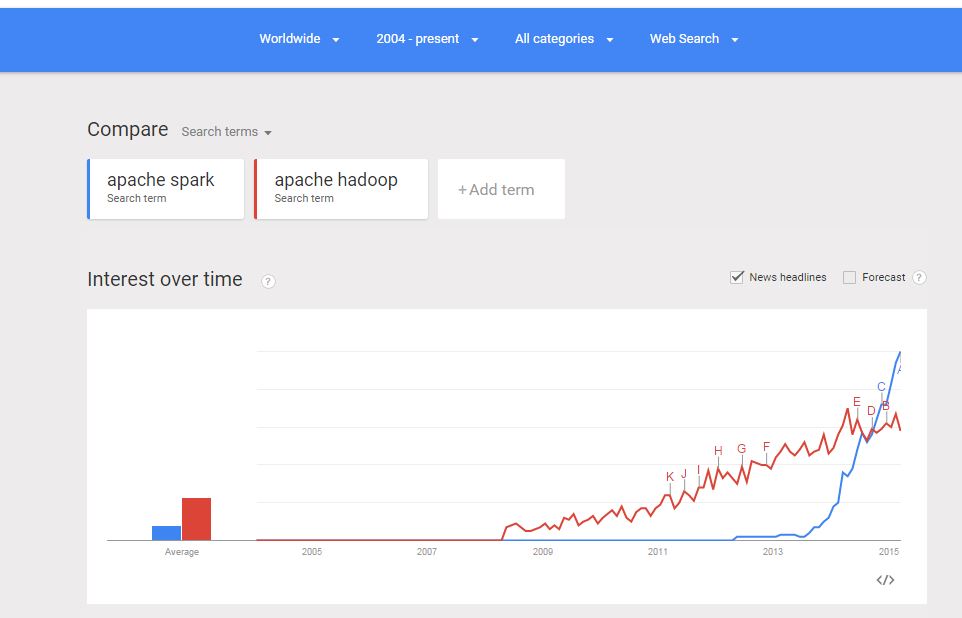
Apache Spark has created a lot of buzz recently. In fact, beyond the buzz, Apache Spark has seen phenomenal adoption and has been marked out as the successor to Hadoop MapReduce.
Google Trends confirms the hockey stick like growth in interest in Apache Spark. All leading Hadoop vendors, including Cloudera, now include Apache Spark in their Hadoop distribution.
So what exactly is Spark, and why has it generated such enthusiasm? Apache Spark is an open-source big data processing framework designed for speed and ease of use. Spark is well-known for its in-memory performance, but that has also given rise to misconceptions about its on-disk abilities. Spark is in fact a general execution engine - which has a greatly improved performance both in-memory as well as on-disk, when compared with older frameworks like MapReduce. With its advanced DAG (directed acyclic graph) execution engine, Spark can run programs up to 100x faster than MapReduce in memory, or 10x faster on-disk.
Machine Learning is a big part of big data and data science. A subset of artificial intelligence - a branch of science notorious for requiring advanced knowledge of mathematics. In practice though, most data scientists don’t try to build a Chappie and there are simpler, practical ways to get started with machine learning.
Machine learning in practice involves predictions based on data. Notable examples include Amazon’s product recommendations with the “customers also bought” scroll-list, or Gmail’s priority inbox or any email spam-filter feature. How do these work? For Amazon, clicks by the user is used to learn and predict user behavior and propensity (likelihood) to buy certain items. The items the user is most likely to buy are then displayed on the recommendation system. Gmail’s system learns from the messages which the user reads and/replies to and prioritizes them.