The technology world often sees upheavals when disparate concepts are put together to achieve different objectives, creating something which is much more than the sum of its parts. Delta Lake is one such concept, which has melded log and ACID, bringing transaction and atomicity concepts into the ETL-analytics-big.data field, creating a revolution of sorts.
The problem(s):
Since traditional data warehousing, the design and modeling of analytics systems relied on denormalized tables, as analytics systems were considered separate from transactional systems. This started to change with the move to the cloud and availability of more real-time data. With the advent of big data technology like HDFS/Hadoop, additional constraints on updates and storage of relational datasets were added due to performance costs. The difficulty was particularly acute for cloud customers who faced additional latency compared to on-premises HDFS/Hadoop users.
GDPR compliance meant deleting or correcting customer data required massive table-wide updates for a few records, with increased probability of data corruption and consistency issues in case of crashed updates.
There were a few common ways to work around these problems:
- Partitioning relational data based on fields like dates, and using columnar data formats like Parquet or ORC and,
- Using Apache Spark SQL, Presto or Hive for queries to apply an SQL abstraction on the underlying datasets. However these quickly became complicated to maintain in case of complex updates and led to its own performance issues.
Databricks develops the Delta Lake
The solution came in the form of the Delta Lake, an innovation from Databricks, which started offering it to its customers from 2017 and finally open sourced in 2019.
The Delta Lake is an ACID table storage layer on top of cloud object stores or the data lake. It adds ACID transactions and schema enforcement capabilities to data lakes.
- The innovation was to maintain information about which objects are part of a Delta table in an ACID manner, using a write-ahead log, which itself is stored in the cloud data lake.
- Each transaction is recorded as a new entry in the log, including metadata about the operation(CRUD) and the version of the data. For performance, the logs is compressed periodically into checkpoints. This design eliminates the need to maintain a separate metastore.
- Delta lake supports the highest isolation level:
serializableso that concurrently executing transactions appear to be serially executing.
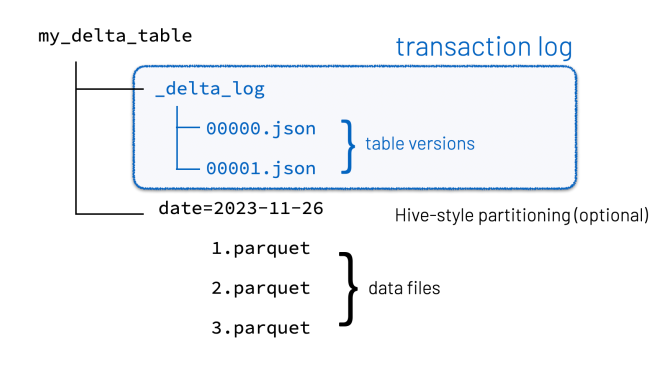
(Image adapted from Denny Lee)
Key features
- Updates and Deletes - support for upserts (update + insert) and deletes.The
delta logis crucial to support atomic ACID transactions. - Optimistic concurrency control - used to managed concurrent writes. Similar to an RDBMS, this supports maintaining isolation
- Time travel - Use of versioned Parquet files allows data versioning and enables
time travelor querying point-in-time snapshots and perform rollbacks. - Schema enforcement and evolution - allows reading old Parquet files without rewriting them if a table’s schema changes.
- File-skipping - Delta Lake stores file-level metadata information: the min/max values of each column for each file in the table. This allows a powerful optimization called
file skippingwhich can make some queries run 100 times faster!
The Lakehouse
These features of the Delta Lake have popularized the concept of the lakehouse, something with combines some of the best features of data lakes and data warehouses.
In essence, the Delta Lake Lakehouse sits in between data lakes and data warehouses.
| Parameter | Data warehouse | Lakehouse | Data Lake |
|---|---|---|---|
| Type of data | Structured data only | Both structured and unstructured data | Both structured and unstructured data |
| Storage | RDBMS, usually rows | Parquet, columns | Various formats: HDFS/Avro/Parquet |
| Schema enforcement | Strict schema-on-write | Schema-on-read, optional schema-on-write | Schema-on-read |
| Scalability | Complex partitioning | Can scale horizontally | Can scale horizontally |
| Concurrency | Not optimized for updates | Supports concurrent writes and ACID transactions | No transaction support, possible non-repeatable reads |
| ETL and CDC | Complex ETL and CDC | In-between complexity | Less complex with ELT |
| SCD^ | Supported | Supported e.g. with upserts | Not supported natively |
In the lakehouse architecture, data is ingested into the data lake using a schema-on-read approach. However, the Lakehouse also allows schema enforcement (schema-on-write) through ACID transactions and seamless schema evolution. This combination of schema-on-read and schema-on-write allows for a flexible and iterative approach to data exploration and analysis.
Streaming data
Delta Lake provides a unified table format that can be used for both batch and streaming data processing.
Apache Kafka is often used to manage streaming pipelines or aggregate data in real-time, which could add management complexity and duplicate data. Delta Lake supports exactly-once streaming writes and could in many cases obviate the need for specialized real-time data processing systems.
Delta lakes and the Lakehouse architecture bridge the gap between data lakes and data warehouses with their best-of-both-worlds features. With increasing cloud adoption, startups like Dremio as well as all major cloud providers offer lakehouse-like services:
- Amazon:
AWS Redshift Spectrum - Microsoft:
Azure Synapse + ADLS - Google:
GCP BigQuery + BigLake
Open-source lakehouse spawns include Apache Iceberg and Apache Hudi.
Integration and orchestration platforms like Apache Airflow and Apache Nifi also offer enhanced capabilities within the lakehouse.
While originally developed by Databricks, Delta Lake is now an open-source project of the Linux Foundation, with multiple contributors like Amazon, Talend, Microsoft, ByteDance or Alibaba.
^SCD: Slowly changing dimension
References:
- Armbrust et al. Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores | Paper:
- Databricks open sources Delta Lake
- Delta Lake file skipping
- Understanding the Delta Lake transaction log at the file level